TTS-chatbot
Overview
This project presents the development of a cross-platform chatbot with integrated Text-to-Speech (TTS) capabilities, designed and implemented by Shun Guo as part of the Duke Kunshan University Signature Work program. The chatbot was designed to operate across multiple social platforms such as QQ and WeChat, aiming to enhance human-machine interaction with natural-sounding voice responses.
Project Highlights
Objective: To integrate modern deep learning-based TTS algorithms into a chatbot for deployment on various social platforms, improving user experience through natural voice interaction.
TTS Systems Explored: The project focused on comparing two leading TTS models:
- Tacotron 2 (Google)
- VITS (Conditional Variational Autoencoder with Adversarial Learning)
Evaluation Metrics:
- Applied MOSNet, a deep learning-based objective metric to evaluate Mean Opinion Scores (MOS).
- Utilized Mel-Cepstral Distance (MCD) to assess the similarity between generated speech and real human speech samples.

Table 2.1: Algorithms in Text-to-Speech (TTS) tasks
Results:
- VITS outperformed Tacotron 2 in both MOSNet scores and MCD evaluations.
- VITS achieved MOSNet scores of 2.63±0.08, compared to Tacotron 2's 2.56±0.035.
- MCD indicated VITS-generated speech had greater similarity to real human voices.
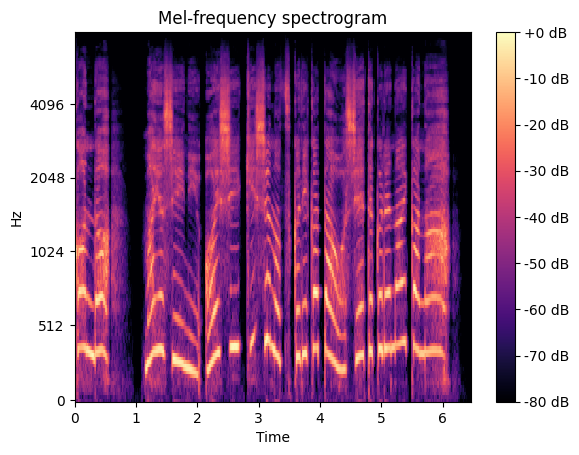
Figure 4.1: Mel-spectrogram of sample data
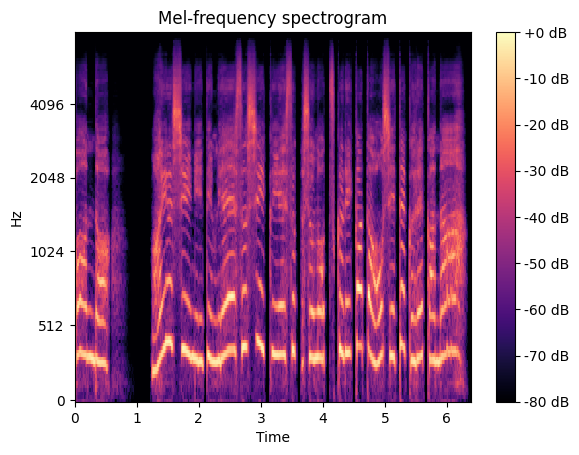
Figure 4.2: Mel-spectrogram of inference data
Technical Stack
- Framework: Nonebot 2 (an open-source, cross-platform chatbot framework)
- Training Data: Multi-language datasets (English, Chinese, Japanese) sourced from public corpora (e.g., VCTK corpus).
- Deployment: Ubuntu 20.04 server via DKU Virtual Computing Management service.
- NLP Integration: Chatbot responses generated via a combination of preset records, NLP APIs (e.g., ChatGPT), and chatbot logs.

Figure 2.1: Nonebot chatbot framework architecture
Key Features
- Multi-language voice response (English, Chinese, Japanese)
- Integration with popular social platforms (e.g., QQ)
- Enhanced user interaction through natural-sounding synthesized speech
- Modular architecture allowing future scalability and language expansion
Tables and Equations
Table 2.1: Algorithms in Text-to-Speech (TTS) tasks
| Name | Description | Publication |
|---|---|---|
| Unit Selection | Select units from existing corpus database | Hunt et al. in 1996 [8] |
| Statistical Parametric Synthesis | Hidden Markov Model to predict waveform | Zen et al. in 2009 [31] |
| Wavenet | Autoregressive PixelRNN | Oord et al. in 2016 [15] |
| Fast Wavenet | Reduce the time complexity of the Wavenet | Paine et al. in 2016 [16] |
| Deep Voice | Multilayer GRU encoder-decoder + hybrid of CNN & RNN | Baidu in 2017 [2] |
| Deep Voice 2 | Same as Deep Voice with more WaveNet layers | Baidu in 2017 [5] |
| Deep Voice 3 | FCN Encoder-Decoder | Google in 2017 [17] |
| Tacotron | CHBG and RNN Encoder-Decoder | Google in 2017 [28] |
| Tacotron 2 | LSTM and RNN encoder-decoder | Google in 2018 [20] |
| VITS | cVAE + GAN | Kim et al. in 2021 [9] |
Equation 3.1: STFT Formula
Equation 4.2: MCD Formula
Conclusion
The project demonstrates the potential of deep learning TTS systems to significantly improve chatbot-human interaction by adding natural speech capabilities. While VITS was identified as the superior model, limitations such as slow response generation and evaluation accuracy were noted, paving the way for further enhancements in future iterations.

Figure 3.3: Structure of GAN

Figure 3.3: Structure of GAN

Equation 3.1: STFT Formula
The original report
PDF preview unavailable in this view. Please download instead: